Parallel Replicas
Introduction
ClickHouse processes queries extremely quickly, but how are these queries distributed and parallelized across multiple servers?
In this guide, we will first discuss how ClickHouse distributes a query across multiple shards via distributed tables, and then how a query can leverage multiple replicas for its execution.
Sharded architecture
In a shared-nothing architecture, clusters are commonly split into multiple shards, with each shard containing a subset of the overall data. A distributed table sits on top of these shards, providing a unified view of the complete data.
Reads can be sent to the local table. Query execution will occur only on the specified shard, or it can be sent to the distributed table, and in that case, each shard will execute the given queries. The server where the distributed table was queried will aggregate the data and respond to the client:
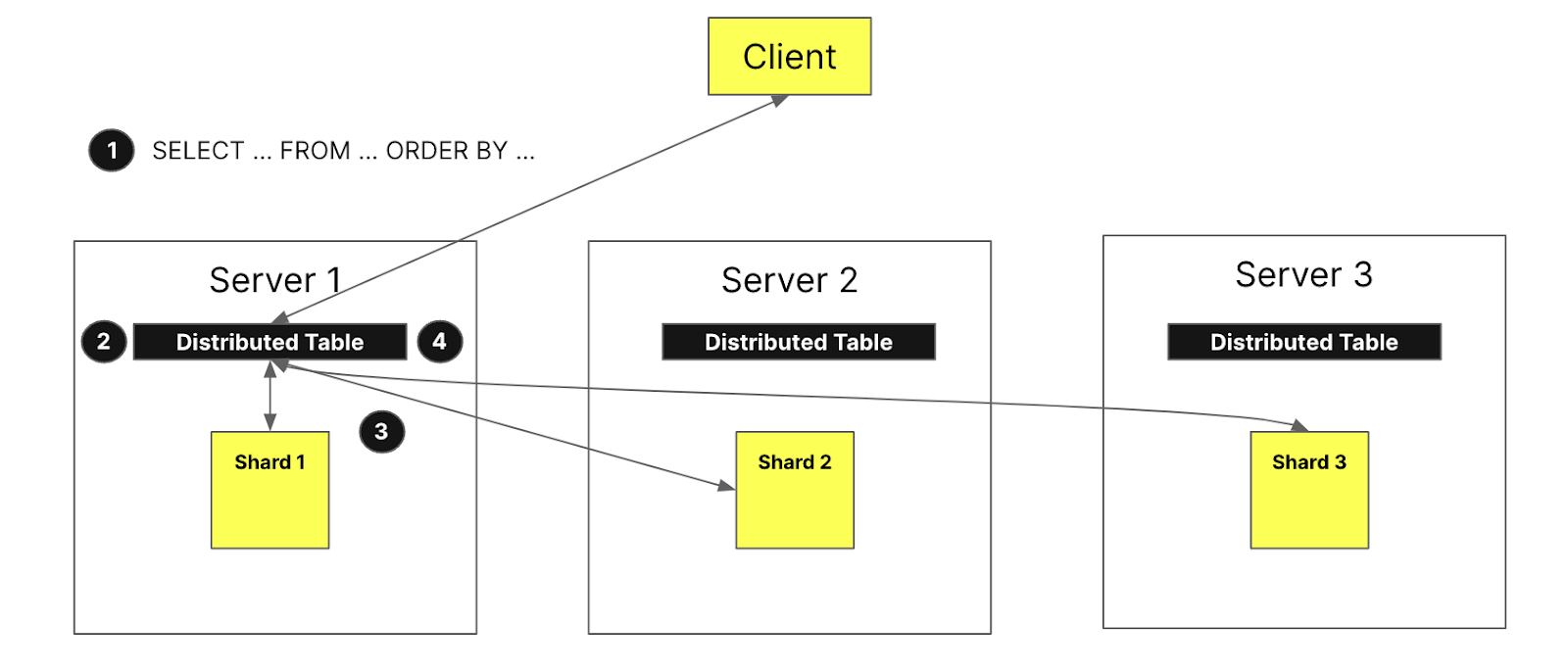
The figure above visualizes what happens when a client queries a distributed table:
The select query is sent to a distributed table on a node arbitrarily (via a round-robin strategy or after being routed to a specific server by a load balancer). This node is now going to act as a coordinator.
The node will locate each shard that needs to execute the query via the information specified by the distributed table, and the query is sent to each shard.
Each shard reads, filters, and aggregates the data locally and then sends back a mergeable state to the coordinator.
The coordinating node merges the data and then sends the response back to the client.
When we add replicas into the mix, the process is fairly similar, with the only difference being that only a single replica from each shard will execute the query. This means that more queries can then be processed in parallel.
Non-sharded architecture
ClickHouse Cloud has a very different architecture to the one presented above. (See "ClickHouse Cloud Architecture" for more details). With separation of compute and storage, and with virtually an infinite amount of storage, the need for shards becomes less important.
The figure below shows the ClickHouse Cloud architecture:
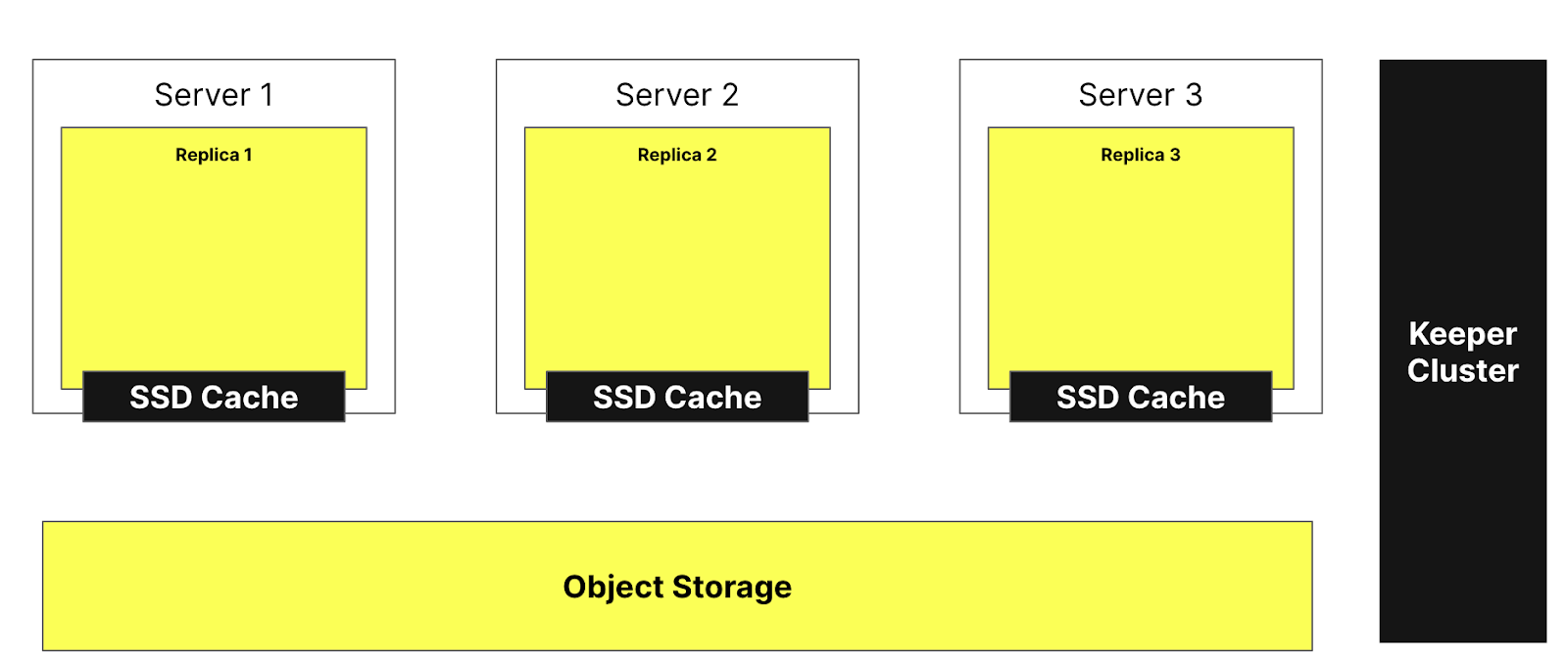
This architecture allows us to be able to add and remove replicas nearly instantaneously, ensuring a very high cluster scalability. The ClickHouse Keeper cluster (shown right) ensures that we have a single source of truth for the metadata. Replicas can fetch the metadata from the ClickHouse Keeper cluster and all maintain the same data. The data themselves are stored in object storage, and the SSD cache allows us to speed up queries.
But how can we now distribute query execution across multiple servers? In a sharded architecture, it was fairly obvious given that each shard could actually execute a query on a subset of the data. How does it work when there is no sharding?
Introducing parallel replicas
To parallelize query execution through multiple servers, we first need to be able to assign one of our servers as a coordinator. The coordinator is the one that creates the list of tasks that need to be executed, ensures they are all executed, aggregated and that the result is returned to the client. Like in most distributed systems, this will be the role of the node that receives the initial query. We also need to define the unit of work. In a sharded architecture, the unit of work is the shard, a subset of the data. With parallel replicas we will use a small portion of the table, called granules, as the unit of work.
Now, let's see how it works in practice with the help of the figure below:
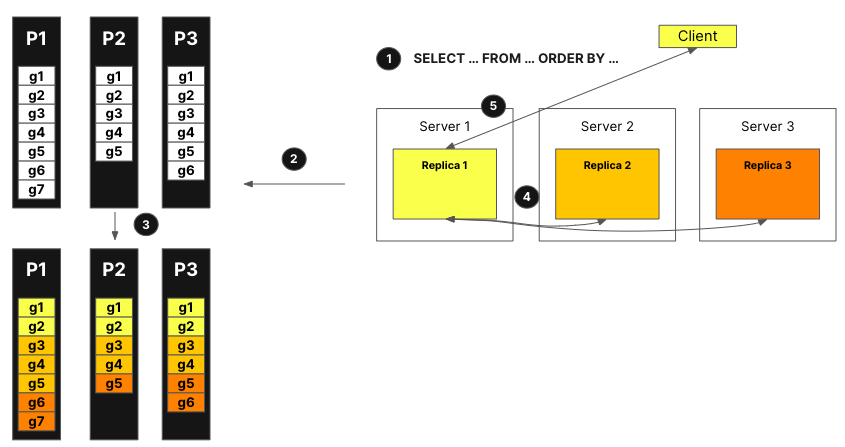
With parallel replicas:
The query from the client is sent to one node after going through a load balancer. This node becomes the coordinator for this query.
The node analyzes the index, and selects the right parts and granules to process.
The coordinator splits the workload into a set of granules that can be assigned to different replicas.
Each set of granules gets processed by the corresponding replicas and a mergeable state is sent to the coordinator when they are finished.
Finally, the coordinator merges all the results from the replicas and then returns the response to the client.
The steps above outline how parallel replicas work in theory. However, in practice, there are a lot of factors that can prevent such logic from working perfectly:
Some replicas may be unavailable.
Replication in ClickHouse is asynchronous, some replicas might not have the same parts at some point in time.
Tail latency between replicas needs to be handled somehow.
The filesystem cache varies from replica to replica based on the activity on each replica, meaning that a random task assignment might lead to less optimal performance given the cache locality.
We explore how these factors are overcome in the following sections.
Announcements
To address (1) and (2) from the list above, we introduced the concept of an announcement. Let's visualize how it works using the figure below:
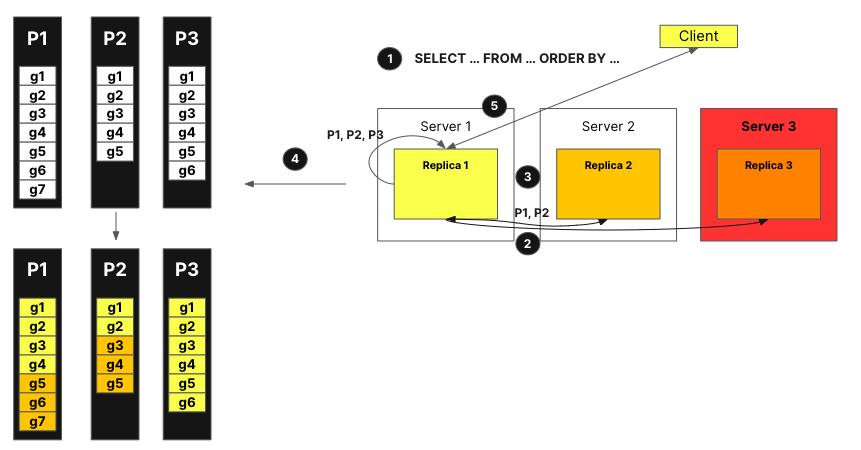
The query from the client is sent to one node after going through a load balancer. The node becomes the coordinator for this query.
The coordinating node sends a request to get announcements from all the replicas in the cluster. Replicas may have slightly different views of the current set of parts for a table. As a result we need to collect this information to avoid incorrect scheduling decisions.
The coordinating node then uses the announcements to define a set of granules that can be assigned to the different replicas. Here for example, we can see that no granules from part 3 have been assigned to replica 2 because this replica did not provide this part in its announcement. Also note that no tasks were assigned to replica 3 because the replica did not provide an announcement.
After each replica has processed the query on their subset of granules and the mergeable state has been sent back to the coordinator, the coordinator merges the results and the response is sent to the client.
Dynamic coordination
To address the issue of tail latency, we added dynamic coordination. This means that all the granules are not sent to a replica in one request, but each replica will be able to request a new task (a set of granules to be processed) to the coordinator. The coordinator will give the replica the set of granules based on the announcement received.
Let's assume that we are at the stage in the process where all replicas have sent an announcement with all parts.
The figur below visualizes how dynamic coordination works:
Replicas let the coordinator node know that they are able to process tasks, they can also specify how much work they can process.
The coordinator assigns tasks to the replicas.
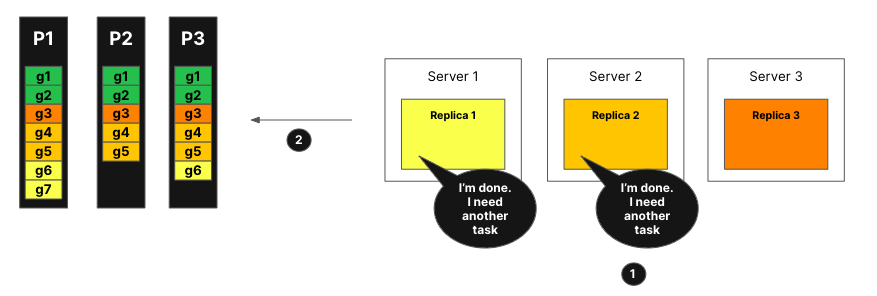
Replica 1 and 2 are able to finish their task very quickly. They will request another task from the coordinator node.
The coordinator assigns new tasks to replica 1 and 2.
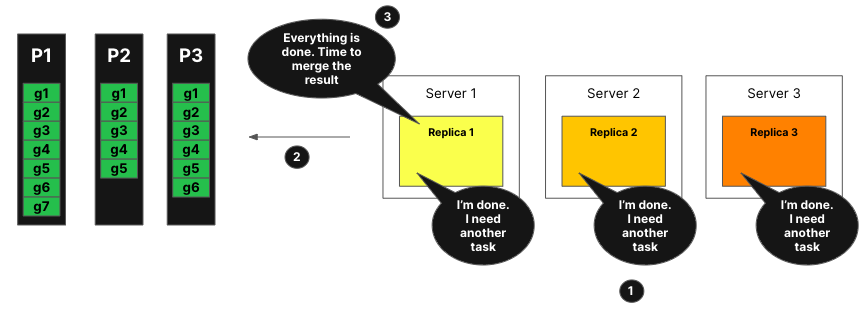
All the replicas are now done with the processing of their task. They request more tasks.
The coordinator, using the announcements, checks what tasks remain to be process, but there are no remaining tasks.
The coordinator tells the replicas that everything has been processed. It will now merge all the mergeable states and respond to the query.
Managing cache locality
The last remaining potential issue is how we handle cache locality. If the query is executed multiple times, how can we ensure the same task gets routed to the same replica? In the previous example, we had the following tasks assigned:
| Replica 1 | Replica 2 | Replica 3 | |
|---|---|---|---|
| Part 1 | g1, g6, g7 | g2, g4, g5 | g3 |
| Part 2 | g1 | g2, g4, g5 | g3 |
| Part 3 | g1, g6 | g2, g4, g5 | g3 |
To ensure that the same tasks are assigned to the same replicas and can benefit from the cache, two things happen. A hash of the part + set of granules (a task) gets computed. A modulo of the number of replicas for the task assignment gets applied.
On paper this sounds good, but in reality, a sudden load on one replica, or a
network degradation, can introduce tail latency if the same replica is
consistently used for executing certain tasks. If max_parallel_replicas is less
than the number of replicas, then random replicas are picked for query execution.
Task stealing
if some replica processes tasks slower than others, other replicas will try to 'steal' tasks that in principle belong to that replica by hash to reduce the tail latency.
Limitations
This feature has known limitations, of which the major ones are documented in this section.
If you find an issue which is not one of the limitations given below, and
suspect parallel replica to be the cause, please open an issue on GitHub using
the label comp-parallel-replicas.
| Limitation | Description |
|---|---|
| Complex queries | Currently parallel replica works fairly well for simple queries. Complexity layers like CTEs, subqueries, JOINs, non-flat query, etc. can have a negative impact on query performance. |
| Small queries | If you are executing a query that does not process a lot of rows, executing it on multiple replicas might not yield a better performance time given that the network time for the coordination between replicas can lead to additional cycles in the query execution. You can limit these issues by using the setting: parallel_replicas_min_number_of_rows_per_replica. |
| Parallel replicas are disabled with FINAL | |
| High Cardinality data and complex aggregation | High cardinality aggregation that needs to send much data can significantly slow down your queries. |
| Compatibility with the new analyzer | The new analyzer might significantly slow down or speed up query execution in specific scenarios. |
Settings related to parallel replicas
| Setting | Description |
|---|---|
enable_parallel_replicas | 0: disabled1: enabled 2: Force the usage of parallel replica, will throw an exception if not used. |
cluster_for_parallel_replicas | The cluster name to use for parallel replication; if you are using ClickHouse Cloud, use default. |
max_parallel_replicas | Maximum number of replicas to use for the query execution on multiple replicas, if a number lower than the number of replicas in the cluster is specified, nodes will be selected randomly. This value can also be overcommitted to account for horizontal scaling. |
parallel_replicas_min_number_of_rows_per_replica | Help limiting the number of replicas used based on the number of rows that need to be processed the number of replicas used is defined by: estimated rows to read / min_number_of_rows_per_replica. |
allow_experimental_analyzer | 0: use the old analyzer1: use the new analyzer. The behavior of parallel replicas might change based on the analyzer used. |
Investigating issues with parallel replicas
You can check what settings are being used for each query in the
system.query_log table. You can
also look at the system.events
table to see all the events that have occured on the server, and you can use the
clusterAllReplicas table function to see the tables on all the replicas
(if you are a cloud user, use default).
Response
The system.text_log table also
contains information about the execution of queries using parallel replicas:
Response
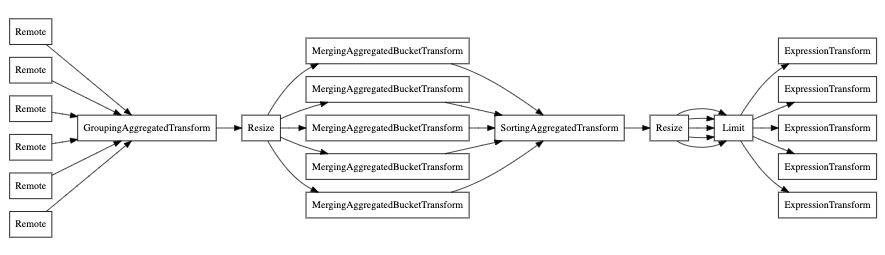
Finally, you can also use the EXPLAIN PIPELINE. It highlights how ClickHouse
is going to execute a query and what resources are going to be used for the
execution of the query. Let’s take the following query for example:
Let’s have a look at the query pipeline without parallel replica:
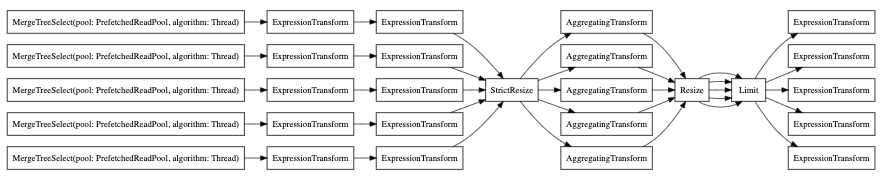
And now with parallel replica: